

A structured program produced genetic sequences that don’t exist in nature — then those sequences were built, tested in human cells, and found to work. That single result points to something larger: biology is beginning to look less like a collection of disconnected experiments and more like a programmable system. Proto is the language making that possible — letting researchers compose designs across DNA, RNA, proteins, and ligands, while AI agents translate plain-English instructions into working molecular workflows. What gets designed next may be limited only by what we’re bold enough to ask for.
The research team at Stanford University and the Arc Institute in Palo Alto, California, has built something that many in the biological research community have quietly been waiting for: a unified language that lets scientists actually use the explosion of biological AI tools that have emerged over the past few years, without needing to be a software engineer to do it.
The Problem Nobody Was Talking About Loudly Enough
Here is a reality that anyone who has worked in computational biology will recognize immediately. Powerful AI models for protein design, RNA engineering, and genomics have been arriving at a rapid pace. But getting them to work together? That has been a completely different story.
Ben Viggiano put it plainly: before Proto existed, the first one to three weeks of any biological design project he worked on went entirely to setup. Reconciling conflicting software dependencies, managing hardware demands, building custom pipelines from scratch, all before a single useful result was produced. And if one small implementation error crept in somewhere along the way, it could silently produce bad designs, wasting weeks of experimental time and significant research budget before anyone caught the mistake.
This is the unglamorous reality that Proto was built to fix.
So What Exactly Is Proto?
At its heart, Proto is a high-level programming language for generative biology. It takes the messy, complicated process of biological design and organizes it around four clean, intuitive building blocks, what the team calls primitives.
These four primitives are sequences, generators, constraints, and optimizers. A sequence is simply the molecular string being designed, whether that is DNA, RNA, or a protein. A generator proposes candidate sequences. A constraint scores how good a candidate actually is. And an optimizer steers the whole process toward sequences that satisfy all the desired goals simultaneously.
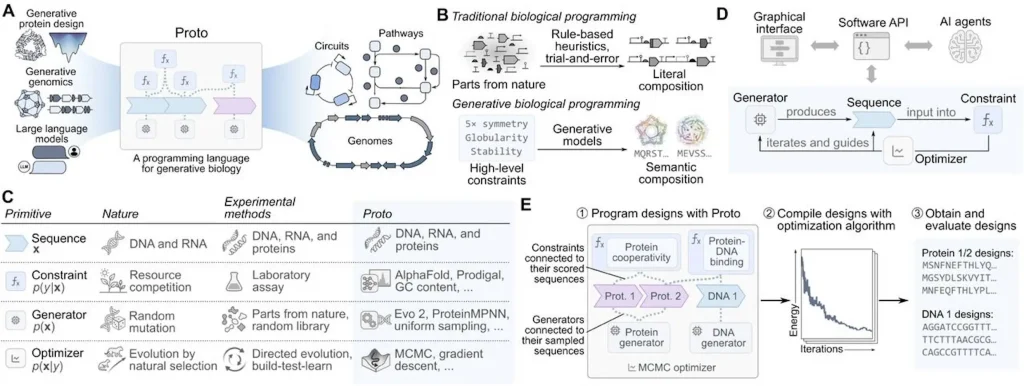
Image Source: https://www.biorxiv.org/content/10.64898/2026.06.22.733870v1
What makes this elegant is that the same four primitives apply to almost any biological design task. Designing an antibody and designing a gene promoter look completely different on the surface, but both follow the same underlying logic. Brian Hie pointed out that once you see any design challenge through this shared framework, you immediately know where in the process you are and what you need next.
Researchers drew a beautiful parallel to evolution itself. Nature has been running its own version of this loop for billions of years, sequences, selection pressure as a constraint, random mutations as proposals, and fitness as the optimization target. Proto is, in a sense, letting scientists run a deliberate and guided version of that same process.
What Proto Has Already Demonstrated
The team did not just build infrastructure and stop there. They put Proto to the test on some genuinely difficult biological challenges.
In one set of experiments, they used Proto to design intronic sequences that behave differently in different cell types, splicing correctly in one cell line while disrupting gene function in another. This kind of cell-type-specific control is enormously valuable for therapeutic applications. Previous methods required testing thousands of candidates to find anything that worked. Proto found functional designs after testing only tens of candidates.
The more complex challenge involved designing synthetic promoter-repressor pairs, a DNA regulatory element, and a protein that specifically recognizes and binds it, without interfering with anything else in the cell. This required simultaneously optimizing two different molecular types across multiple objectives. Proto achieved success rates comparable to existing specialized approaches, again while testing only tens of designs rather than running high-throughput screens.
One result that genuinely surprised even the researchers: the AI system discovered cryptic splice sites, alternative biological mechanisms that the scientists had not anticipated, to achieve the design goal. When you specify what you want at a high level and let the models figure out how to get there, sometimes the solution is one a human would never have thought of.
A Platform Built to Grow
Proto comes with both a drag-and-drop graphical interface for wet lab biologists who may not write code and a Python API for computational scientists who want full control. It currently supports over 120 biological AI tools, all managed in isolated environments so their dependencies never conflict.
The team is clear that Proto is not meant to replace experiments or the expertise of working biologists. It is meant to give researchers better starting points, fewer candidates to test, each one more carefully reasoned. The goal, as Aditi Merchant described it, is a future where biological design is limited not by which natural parts exist, but by human creativity.
Article Source: Reference Paper | Reference Article | Availability: Website
Disclaimer:
The research discussed in this article was conducted and published by the authors of the referenced paper. CBIRT has no involvement in the research itself. This article is intended solely to raise awareness about recent developments and does not claim authorship or endorsement of the research.
Important Note: bioRxiv releases preprints that have not yet undergone peer review. As a result, it is important to note that these papers should not be considered conclusive evidence, nor should they be used to direct clinical practice or influence health-related behavior. It is also important to understand that the information presented in these papers is not yet considered established or confirmed.
Follow Us!
Learn More:




Anchal is a consulting scientific writing intern at CBIRT with a passion for bioinformatics and its miracles. She is pursuing an MTech in Bioinformatics from Delhi Technological University, Delhi. Through engaging prose, she invites readers to explore the captivating world of bioinformatics, showcasing its groundbreaking contributions to understanding the mysteries of life. Besides science, she enjoys reading and painting.











{kind=link}