
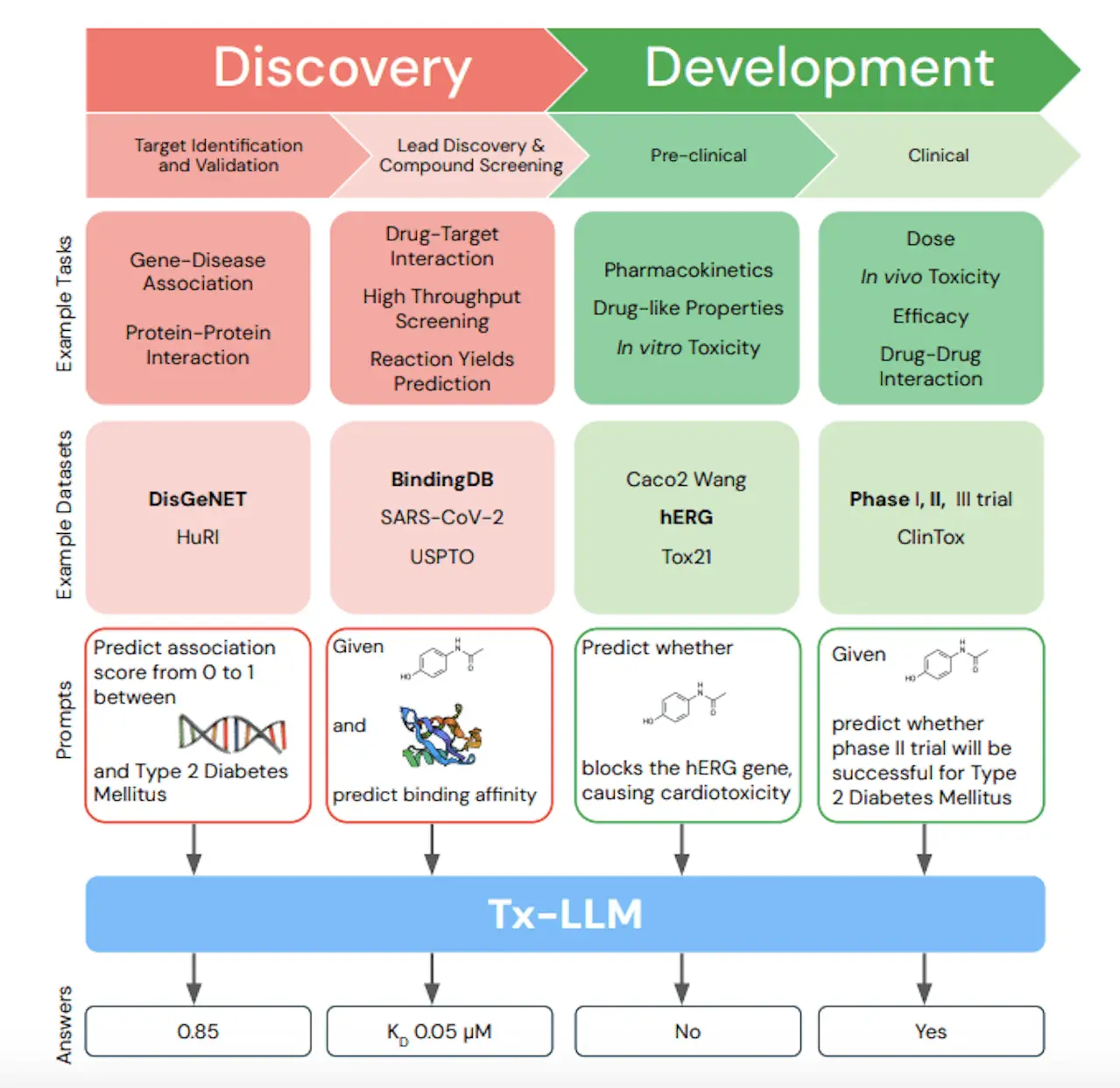
The field of medicine has had big news. Scientists from Google Research and Google DeepMind unveil Tx-LLM, a new tool that helps speed up the complex drug discovery process. Tx-LLM is a large language model (LLM) optimized for pharmaceutical development. It is fine-tuned from PaLM-2 and is set to advance LLMs in biochemistry, potentially becoming a comprehensive tool for drug discovery and development.
Creating new medicines would be a fast and efficient endeavor. Out of all the drug candidates that are tested in clinical trials, only a microscopic proportion gets through. Moreover, it can take over ten years for a drug to go from being a concept to the moment when it is put on sale in pharmacies. The reason why this process is so slow is because of drugs themselves that are hard to understand well enough. First-rate medicine must not just interact with its target but also avoid damaging patients who use it; it needs to be producible and have properties that will allow one to deliver it effectively inside the body. To navigate their way through this intricate pipeline, researchers traditionally employed lab experiments supplemented by bioinformatics tools and good old intuition.
What is Tx-LLM?
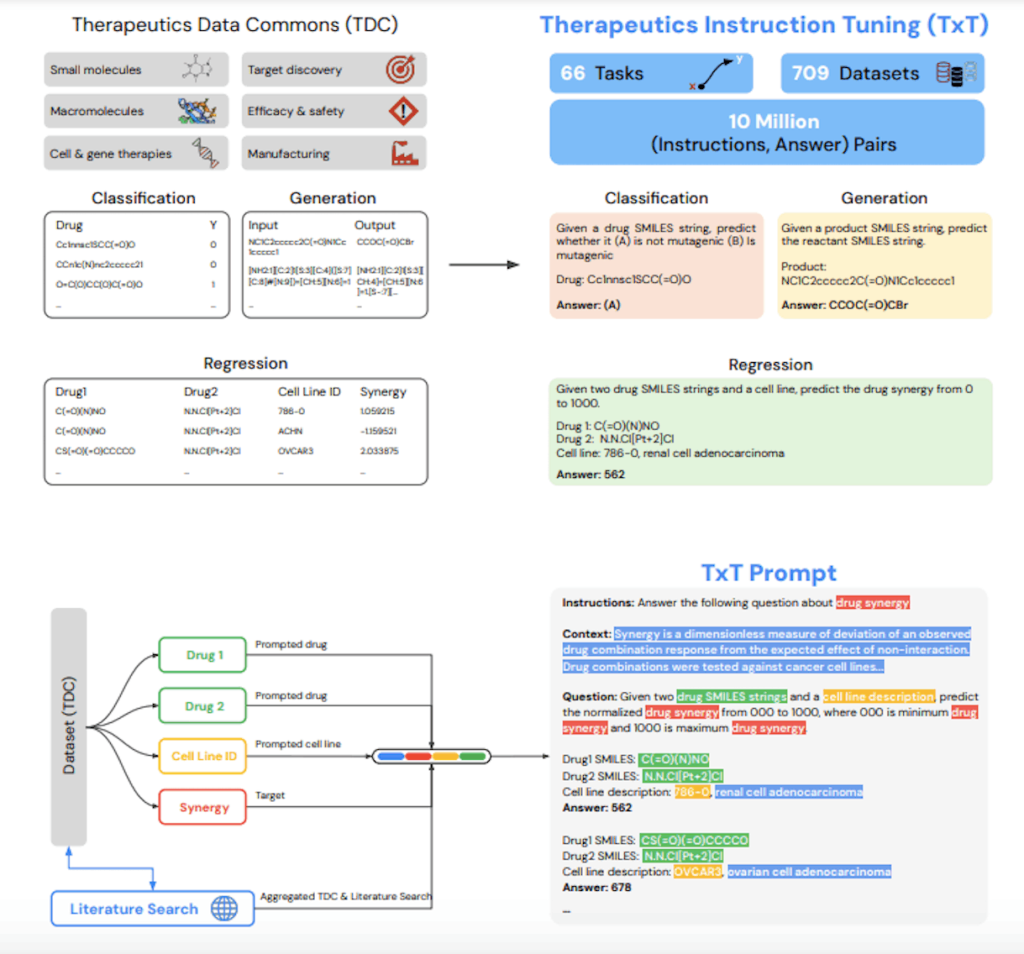
LLMs are a type of artificial intelligence that can process and generate large amounts of text. They are given immense amounts of code and text, exposing them to different patterns and relationships between words. However, Tx-LLM goes a notch higher where it is trained not only on texts but also on chemical structures plus other scientific data that pertains to drugs. This means that it understands the linkages between the structure of drugs, their properties, and their therapeutic possibilities.
How Does Tx-LLM Work?
The researchers responsible for developing Tx-LLM built their model by modifying an already existing LLM named PaLM-2. Then, they further improved this foundation model by training it using a variety of data sets for drug discovery.
These datasets incorporated the following:
Chemical structures: Tx-LLM learned how to pick out the constituents of medicinal compounds like small molecules, proteins, and nucleic acids.
Biological data: The model was trained on cellular, genomic, and disease information to give a sense of where in-life drugs are situated.
Scientific text: Tx-LLM has been exposed to research papers and other scientific documents, thereby allowing it to absorb knowledge and insights made by human scientists.
Experimental data: Significantly, real-world experimental data was used in training Tx-LLM, thus enabling it to learn how drugs behave within a living organism in terms of their properties.
This diverse training dataset allows Tx-LLM to perform a wide range of tasks relevant to drug development, which include:
Drug targets prediction: The model can predict which molecules within a cell will bind to a drug based on its structure.
Drug safety testing: It can determine if drugs have any side effects or whether they would interact with other medications.
Optimizing drug design: Suggesting structural modifications that would make the compound more potent, among other desirable attributes, is one of the capabilities provided by this model, for instance, Thermo Fisher Scientific’s Design-Expert software v1.
Predicting manufacturability: The model can determine if production can be done on a large scale.
The Advantages Of Tx-LLM
Despite the advantages of conventional drug discovery methods, Tx-LLM has several considerations:
Efficiency: The process can be expedited by using automation in many stages of drug development.
Precision: Discovering useful drugs that would not have been found in traditional ways is possible since the model can analyze large volumes of data.
Cost Savings: Financial savings may result from this technology, such as long drought-like incubation periods and higher chances of mature products being developed.
Holistic Approach: Considering the above facts, Tx-LLM looks at the whole pipeline, unlike other techniques that focus on individual stages leading to a broader diversity of drugs.
The Future Of Tx-LLM
This study demonstrates that Tx-LLM achieves state-of-the-art results on many benchmarks. Moreover, they noted positive transfer between tasks involving different classes of drugs, indicating that Tx-LLM may learn principles about generalizable principles of drug discovery.
Though Tx-LLM has been such a powerful tool, it is important to note that it is still under development. More research should be done to verify its conclusions in real-world settings. Nevertheless, the possible impact of Tx-LLM on drug discovery cannot be underestimated.
This technology could help make the development process faster and more affordable while eventually leading to the production of life-saving drugs.
Join The Conversation
The introduction of Tx-LLM is indeed a great move towards fighting diseases.
If you would like to learn more about this study or AI for drug discovery generally, please let us know by commenting below with your thoughts and queries.
Article Source: Reference Paper
Important Note: arXiv releases preprints that have not yet undergone peer review. As a result, it is important to note that these papers should not be considered conclusive evidence, nor should they be used to direct clinical practice or influence health-related behavior. It is also important to understand that the information presented in these papers is not yet considered established or confirmed.
Follow Us!
Learn More:




Anchal is a consulting scientific writing intern at CBIRT with a passion for bioinformatics and its miracles. She is pursuing an MTech in Bioinformatics from Delhi Technological University, Delhi. Through engaging prose, she invites readers to explore the captivating world of bioinformatics, showcasing its groundbreaking contributions to understanding the mysteries of life. Besides science, she enjoys reading and painting.











{kind=link}