
The versatile workhorses of our cells, proteins, are essential to many biological processes. Numerous scientific endeavors, such as medication research and the creation of biomaterials, depend on our ability to comprehend their structure and function. Protein research has always been a laborious and time-consuming process. However, protein language models (PLMs) are revolutionizing this field by analyzing vast volumes of protein sequence data using artificial intelligence. Research timelines may be significantly shortened by using these algorithms to find hidden patterns in protein sequences. This can be used to anticipate protein characteristics or create novel protein sequences. Although many of the PLMs available today have outstanding features, their reach is sometimes limited. While some people find it easy to create new protein sequences, others find it difficult and prefer to concentrate on studying protein representations. This blog dives into ProLLaMA, a groundbreaking multi-tasking PLM that breaks these barriers and introduces a novel methodology for protein language processing.
The Rise of ProLLMs and the Need for Multitasking
NLG and NLU are only two of the numerous Natural language processing (NLP) tasks that Large Language Models (LLMs) like GPT-x and LLaMA2 are excellent at tackling. Together with its traditional uses, LLMs are increasingly being applied in challenging domains like protein design. Researchers train models with topologies comparable to existing LLMs on a huge protein corpus, using protein sequences as the language. ProLLMs make it possible to quickly generate protein sequences that make sense structurally, which has enormous potential for advancements in biotechnology and medicine. However, there are challenges in extending their capabilities beyond sequence creation.
Natural language processing and protein language processing (PLP) are related fields of study. Unlike LLMs, which cover several jobs in NLP, current ProLLMs concentrate on a single PLP task. ProLLMs have constraints that require innovative solutions to properly exploit them. Understanding the fitness landscape and protein engineering depends on developing a multitasking ProLLM.
However, three main challenges need to be overcome:
Natural Language Requirement: PLP activities demand more than simply protein language to transmit instructions and desired outcomes.
Instruction Following: Current ProLLMs are unable to perform responsibilities as requested by the user.
Consumption of Training Resources: A model’s training on instructions, natural language, and protein language requires a significant amount of resources.
Introducing ProLLaMA: A Multi-Tasking Solution
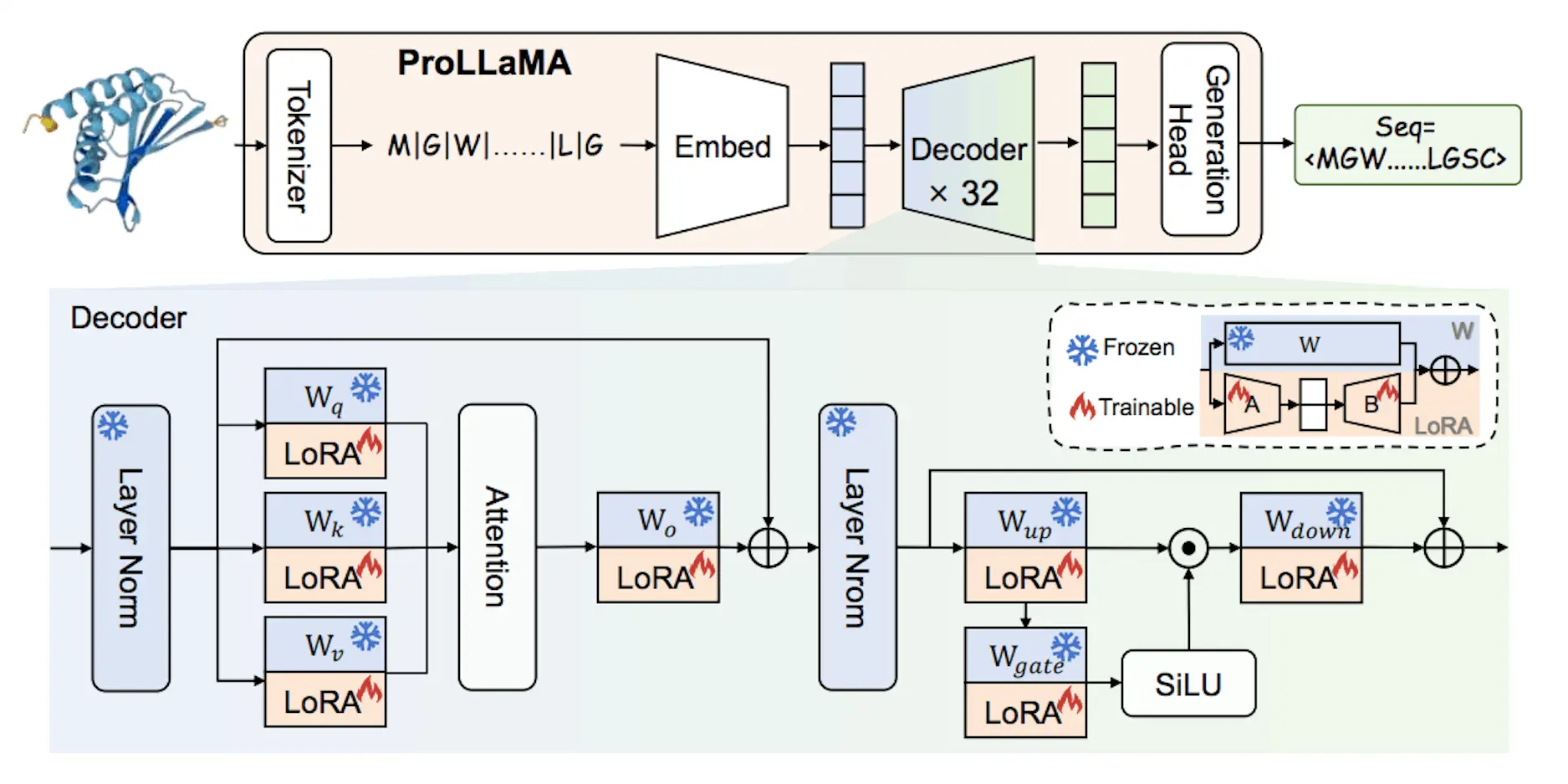
ProLLaMA is a revolutionary Protein Language Large Model (ProLLM) that addresses the shortcomings discussed earlier. Its game-changing training approach is its cornerstone. At its core, ProLLaMA leverages a pre-trained LLM foundation. This LLM is adept at deciphering intricate language patterns, providing ProLLaMA with an understanding of protein language.
ProLLaMA then embarks on a meticulous two-phase training regimen:
Continual Learning:
Current ProLLMs struggle with multitasking due to a lack of natural language abilities. To solve this issue, researchers propose employing a pre-trained LLaMA2 to perform continuous protein language learning. This strategy allows the model to acquire protein language while maintaining its intrinsic linguistic talents, similar to how a human learns a new language. More specifically, they used UniRef50 to generate a dataset. Protein sequences are preprocessed using prefixes and suffixes that they specify. This consistent style lessens confusion by enabling LLaMA2 to distinguish between the new protein language and its prior understanding of natural language.
By training a pre-trained LLaMA2 to continually acquire protein language and utilizing Low-Rank Adaptation (LoRA), researchers were able to build ProLLaMA, a model that comprehends both protein sequence and natural language. As mentioned in the introduction, the researchers were able to resolve the problem of low natural language proficiency and excessive training resource consumption.
Instruction Tuning:
ProLLaMA’s training involves a dedicated stage called “Instruction Tuning”: – Current ProLLMs are unable to do some activities in line with user instructions. To overcome this issue, researchers applied instruction tweaking to the ProLLaMA obtained in the prior stage. They created a multi-task dataset in which each item represents a sample of a task. An assignment consists of two parts: the instructions and the finished result.
Besides, these directives will cause the AI to understand them and do things accordingly, which can be covered in almost any task, such as:
- Controllable Protein Generation: Researchers will be able to produce the protein they want by instructing ProLLaMA, an active tool that can invent unique proteins. ProLLaMA constructs a one-of-a-kind amino acid chain that will fit properly to this function. While this discovery, for instance, puts scientists face to face with the occasion of task-specific protein design such as antibodies, enzyme engineering, etc., on the other hand, it immensely advances biotechnology, thereby creating new possibilities.
- Protein Property Prediction: ProLLaMA thus effectively foresees features of proteins; for instance, structure or function, which is a sequence of amino acids, is the only thing it takes. Consequently, this strategy cuts down on the need for expensive and time-consuming experiments for protein analysis. In this way, researchers may spend less time on routine tests and focus on the most impactful observations for subsequent studies.
ProLLaMA’s adaptability stems from its use of the LoRA method. LoRA enables ProLLaMA to acquire new skills through adjustments in guidance (like fine-tuning) without erasing its fundamental knowledge of protein language gained through ongoing training. This advanced technique makes ProLLaMA a highly flexible and potent tool for researchers.
ProLLaMA: A Multifaceted Language Model
ProLLaMA has been tested and proven to perform better than previous language models. Here’s a look at its skills:
Unconditional Protein Generation:
ProLLaMA can generate original protein sequences that are structurally sound. It maintains this plausibility even for longer sequences, which is a challenge for other models.
Controllable Protein Generation:
When given specific instructions, ProLLaMA might be as well be able to construct proteins that resemble those existing ones having the same structure and actual functional properties. Through this, it directly demonstrates the feasible capacity of encoding genetic code into amino acid structures.
Protein Prediction Enhancements:
ProLLaMA’s exceptional accuracy in predicting protein properties makes it a valuable tool for understanding protein functions without requiring laboratory experiments.
ProLLaMA’s capabilities represent a breakthrough in the understanding of protein language, empowering scientists with a robust tool to address complex challenges in protein science and computational biology.
The Path Forward
ProLLaMA has tremendous potential to transform the scientific environment.ProLLaMA can multitask in the protein industry and might greatly accelerate in the following crucial areas:
- Synthetic Biology
- Protein Science Research
- Biomaterials research and innovation
- Drug discovery
This method makes cutting-edge research more accessible to a wider range of researchers and institutions, particularly those with little funding. This fosters an inclusive AI4Science community.
Conclusion
To summarize, current LLMs are highly effective in a variety of situations. As a result, LLMs might be considered the primary instruments used by biotech researchers. In this study the researchers create and describe a programmed training scheme that converts a general-purpose LLM into a discriminating ProLLM (ProLLM) that can handle a wide range of commercial requirements. They introduced ProLLaMA, a multitask protein language model that is more efficient than the well-known ProLLM and capable of handling many protein-related tasks, such as protein regulation and protein property analysis.
The impact of ProLLaMA is that it constitutes the attainment of a breakthrough in the translation of words that describe these proteins into comprehension. It can not only do complicated calculations but also simple ones in a multi-line system; hence, the possibility of scientific research is wider and more progressive. The employment of ProLLaMA’s concept and technique would likely yield a myriad of crucial effects for the AI4Science category. Thanks to their open-ended manner of addressing individuals and also to the moral development of people, Smart Talking Robot – ProLLAMA – could turn into an instrumental tool to grow expertise in so many areas, thus serving society.
Article source: Reference Paper | Code is available on GitHub
Important Note: arXiv releases preprints that have not yet undergone peer review. As a result, it is important to note that these papers should not be considered conclusive evidence, nor should they be used to direct clinical practice or influence health-related behavior. It is also important to understand that the information presented in these papers is not yet considered established or confirmed.
Follow Us!
Learn More:




Anchal is a consulting scientific writing intern at CBIRT with a passion for bioinformatics and its miracles. She is pursuing an MTech in Bioinformatics from Delhi Technological University, Delhi. Through engaging prose, she invites readers to explore the captivating world of bioinformatics, showcasing its groundbreaking contributions to understanding the mysteries of life. Besides science, she enjoys reading and painting.











 to handle multiple protein language processing (PLP) tasks simultaneously.){kind=link}