
Scientists from Fondazione Poliambulanza Istituto Ospedaliero, Italy, developed a hybrid machine learning/deep learning model to classify patients in two outcome categories, non-ICU, and ICU. With the likelihood score belonging to an outcome class and case-based SHAP interpretation of feature importance, the model intends to give clinical decision support to medical physicians.
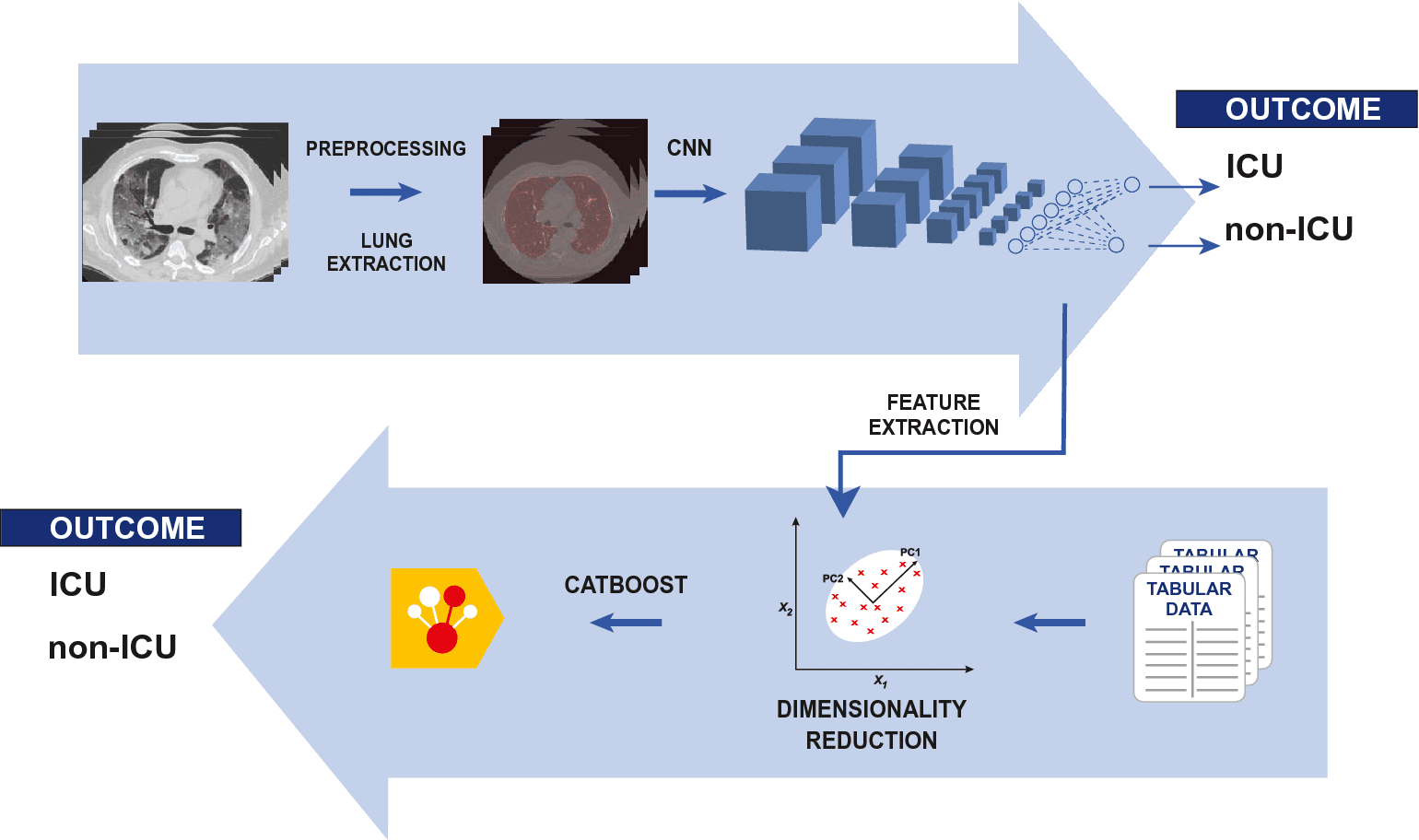
The scientists devised a COVID-19 prognostic hybrid machine learning/deep learning model expected to be usable as a device that will help in clinical decision-making. The proposed model completely incorporates imaging and non-imaging information. A 3D CNN classifier extricates patient-level elements from benchmark CT checks. A CatBoost classifier is applied to extracted features and laboratory and clinical data. The Boruta method is used to pick features in the model, paired with the SHAP feature importance. Such design combines the efficacy of a 3D CNN in creating and selecting patient-level complicated picture characteristics with state-of-the-art machine learning for tabular data. The tool can be used to evaluate data at both a global and individual patient level, with the SHAP relevance of features being used to get the classification percentage score. Such an analytical result is vulnerable to being supplemented by additional information available to the practitioner.
Until now, more than a hundred million people have been accounted for as affected by COVID-19. Over two million deaths have been credited to the disease. From one side of the planet to the other, the sheer quantities of the pandemic represent a significant weight on crisis offices, emergency clinics, concentrated care units, and neighborhood clinical assistance. From the start of the contamination, it was clear that COVID-19 envelops a wide range of clinical introductions and resulting forecasts, with instances of abrupt, innovative development of the clinical and radiological picture. Such components of fluctuation and insecurity are as yet not completely made sense of, with a significant job upheld for an assortment of pathophysiological processes.
It would be normal to attempt to take advantage of artificial intelligence methods, filled by the accessibility of huge information sums, to help clinicians in this unique situation. Without a doubt, many efforts in this sense have proactively been made, headed on different errands, explicitly finding and prognosis. An objective was defined to construct a hybrid machine learning/deep learning severity predictive model that can go about as a helper device for patient risk evaluation in clinical practice.
The fundamental mix of imaging and non-imaging information was considered to achieve the objective. It was decided to take advantage of a 3D Convolutional Neural Network (CNN) as a component extractor and CatBoost, the last age slope supporting model, as a classifier of even data. The result of the model is both the rating score of the result and the SHAP (SHapley Additive exPlanations) assessment of highlight significance in the individual prediction. The SHAP libraries permit computation to include importance in every quiet expectation as game hypothetical SHAP values.
The Proposed Model
The composition of the proposed model consists of a purely 3-Dimensional CNN, having a feature extraction from the last fully connected layer, along with a patient-level classifier on CT images. Apart from this, it consists of a dimensionality decreasing process which includes a Principal Component Analysis (PCA) on retrieved image features a preparatory CatBoost model with a Boruta algorithm having a SHAP feature of importance as the metric. The final component of the proposed model is defined significantly as the CatBoost classifier on the decreased feature space.
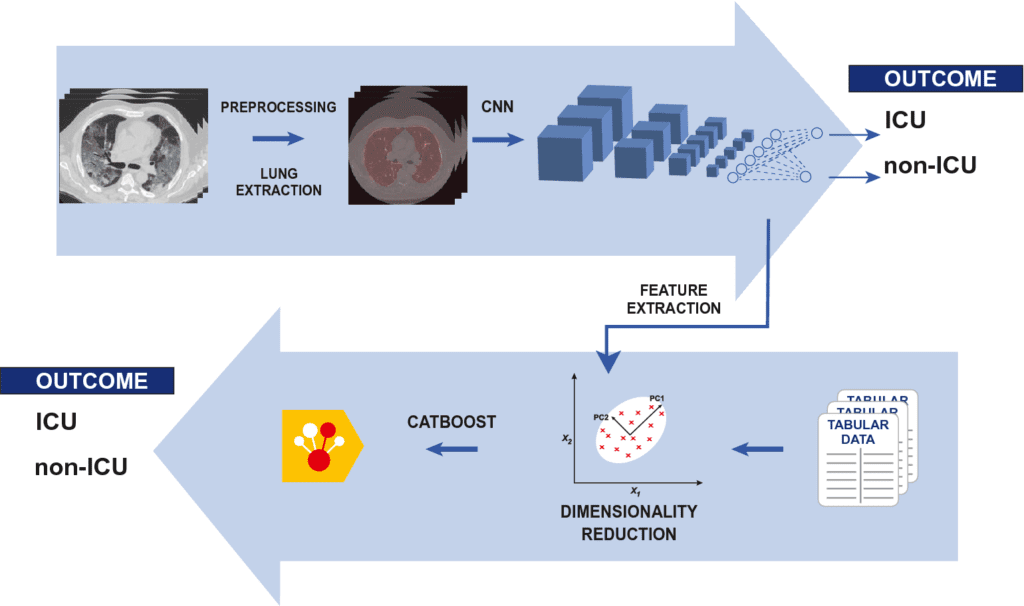
Image Source: A hybrid machine learning/deep learning COVID-19 severity predictive model from CT images and clinical data.
The Imaging and Non-imaging Data Combination
Complex assignments in the center need a combination of radiological data with research facilities and clinical data. Machine learning strategies are beginning to be utilized for such a reason. Other than COVID-19 guess, models can be Alzheimer’s disease classification and progress or the individuation of immunotherapy responders. Radiological data is local as imaging information, while research centers and clinical data come in a forbidden large structure. There is still no agreement on the most effective way to consolidate these two kinds of information in machine learning models. Specifically, CNN showed “unreasonable effectiveness” in picture-related tasks last year.
Be that as it may, the equivalent is essentially not valid for tabular data, where group models, particularly gradient helping varieties (XGBoost, LightGBM, CatBoost), have the edge. Efforts to construct deep learning models devoted to plain information (for example, NODE, TabNet) have shown momentous outcomes in some datasets, yet more fragile execution in others, despite significant complexity.
On a basic level, coordination of imaging and non-imaging data that outfits the force of a neural network in a consolidated model can be reached in various ways. They boil down into four sorts:
- Neural network for division as it were
- Blend of aftereffects of independent imaging and plain models
- Plain information infusion in a deep learning model
- Extraction of learned picture highlights and development of a consolidated plain information model.
The first and maybe the easiest of these methodologies is the utilization of CNN just for division. On such a premise, different quantification records and handcrafted highlights can be determined and taken care of in an even model. Another essential technique is to consolidate the aftereffects of a deep learning classifier on pictures with either clinical/research facility highlights or the autonomous aftereffects of an even model. Both these systems arrived at surprising outcomes.
The other two techniques genuinely mean to assemble a consolidated model, wherein data are intertwined at a lower level to permit full cooperation between different spaces. In the plain infusion approach, non-imaging information is connected at certain places of a deep learning classifier, with a completely associated layer being the undeniable decision. Even information can be infused as they are, or after elaboration, for instance, after at least one completely associated layer. This strategy permits the assembly of completely differentiable models, from end-to-end trainable. It is additionally more straightforward to validate. Surprising models in other fields are for Alzheimer diagnosis, for Alzheimer’s converters early detection, for skin injuries classification. The fourth methodology involves CNN as a picture highlight extractor and a different AI model on the top to work on both pictures extricated and non-picture highlights on equivalent balance. Note that CNN can be pre-trained or prepared without any preparation. This technique enjoys a few benefits. It can take advantage of a condition-of-craftsmanship model for heterogeneous information (for example, slope boosting for removed CNN highlights in XGBoost classifiers). The fundamental machine learning design is less inclined to information starving. It can be easily incorporated with complex feature selection algorithms, and its symmetrical elaboration of non-imaging and image extracted characteristics makes it easier to explain once agnostic features for pictures are acknowledged as such.
Model Building and Training for COVID-19 Prognosis
A CNN classifier permits to pick the significant level portrayal highlights pertinent to the errand. Toward the finish of the organization, a different completely associated layer structure permitted us a progressive decrease of the number of highlights before their extraction to adjust it with non-imaging highlights.
CatBoost was utilized as the machine learning classifier for the final model. CatBoost is turning out to be progressively applied in complex datasets. It carries out Ordered Boosting, and a permutation drove form of helping calculation, and Oblivious Decision Trees, a specific sort of choice tree (too as different elements we don’t treat here). Both ought to be particularly effective in keeping away from overfitting. Hancock and Khoshgoftaar argued that CatBoost’s execution is logical touchy to hyperparameters’ decisions. We especially picked handsome hyperparameters (Ordered Boosting as supporting sort and Bayesian bootstrap type) to choose the arrangement less inclined to overfitting, involving Bayesian improvement for the vast majority of the others. The most influential hyperparameters are the learning rate and the number of trees. CatBoost gives strong tuning strategies individually with the programmed learning rate gauge and the overfitting indicator, both utilized in this approach.
The feature selection in our model is based on implementing the Boruta method with the SHAP metric. The Boruta approach seeks out all relevant features for the job (and the model) rather than a compact subset that minimizes the classifier’s information loss. The SHAP measure takes into account feature interactions and cooperative effects by default. The researchers applied the majority voting technique to take advantage of BorutaSHAP’s benefits while reducing the danger of information loss and the reliance on subsampling unpredictability (Subsection CatBoost model). Because the validation set is used for both the CNN feature extractor and the CatBoost hyperparameter selection, the possibility that some knowledge leaks from the feature extraction through the dimensionality reduction technique and into the hyperparameter selection can’t be ruled out.
The Interpretability of the Model
There is an overall discussion about the need for interpretability of machine learning models for choice making. Notably, European Union regulation evaluates the option to have a clarification of choice made after mechanized information handling (GDPR1671).
A much more grounded push for model logic comes from clinical necessities. Specifically, a logical model isn’t just more adequate for doctors and patients. However, it turns out to be significantly more integrable with extra, out-of-the-model data. In the proposed model, the SHAP investigation gives interpretability worldwide, particularly at a single expectation level. Being extricated from the CNN classifier and the PCA decrease, CT highlights are skeptical.
There are limits to the proposed model. In the first place, the dataset comes from a solitary community, in a limited timeframe, with the subsequent exchange of information homogeneity and speculation power. Second, the quantity of our patients is restricted in contrast with the typical numbers in deep learning classification assignments. Bigger datasets normally will generally lessen model fluctuation. To reduce the influence of these two limits, we took specific consideration in attempting to keep away from overfitting.
This is the right clinical use of machine learning for COVID-19 prognostic errands in the current situation. There is a certain number of COVID-19 prognostic models that utilize radiological and clinical information with deep learning strategies. However, only a few of them are integrated models based on heterogeneous features.
The current study is the first to employ CatBoost on top of the deep learning characteristics extracted. It’s also the first time a gradient boosting model has been applied to COVID-19 prognosis using coupled CNN-derived features, clinical, and laboratory data.
Story Source: Chieregato, M., Frangiamore, F., Morassi, M. et al. A hybrid machine learning/deep learning COVID-19 severity predictive model from CT images and clinical data. Sci Rep 12, 4329 (2022). https://doi.org/10.1038/s41598-022-07890-1.
Learn More:
Top Bioinformatics Books ↗
Learn more to get deeper insights into the field of bioinformatics.
Top Free Online Bioinformatics Courses ↗
Freely available courses to learn each and every aspect of bioinformatics.
Latest Bioinformatics Breakthroughs ↗
Stay updated with the latest discoveries in the field of bioinformatics.
Tanveen Kaur is a consulting intern at CBIRT, currently, she's pursuing post-graduation in Biotechnology from Shoolini University, Himachal Pradesh. Her interests primarily lay in researching the new advancements in the world of biotechnology and bioinformatics, having a dream of being one of the best researchers.











{kind=link}