
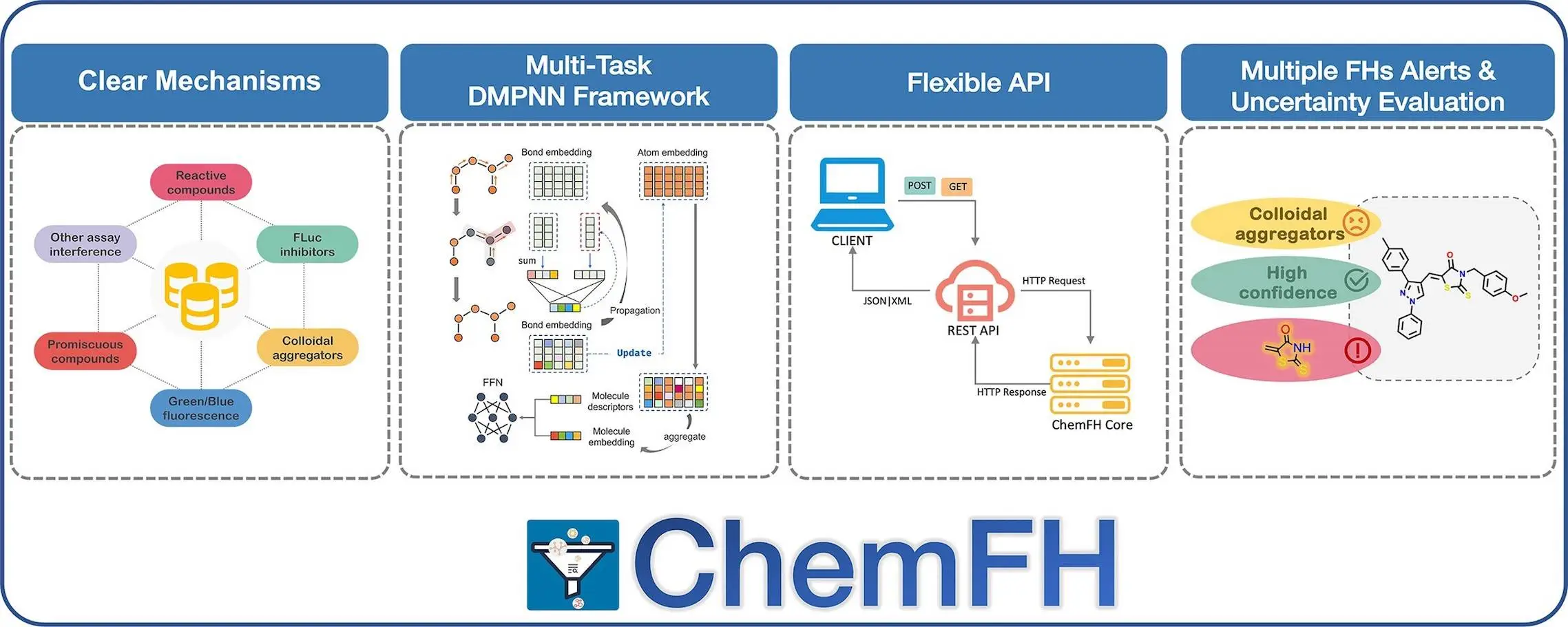
In the drug discovery process, high-throughput screening quickly evaluates a wide range of chemical compounds to find hit compounds for certain biological targets. False-positive results, on the other hand, cause delays in hit compound screening and waste money. In order to address this, scientists from Central South University, China, and collaborators have developed ChemFH, an integrated online platform that allows for the quick virtual assessment of substances that may cause false positive results, such as promiscuous compounds, spectroscopic interference compounds, firefly luciferase inhibitors, chemical reactive compounds, etc.
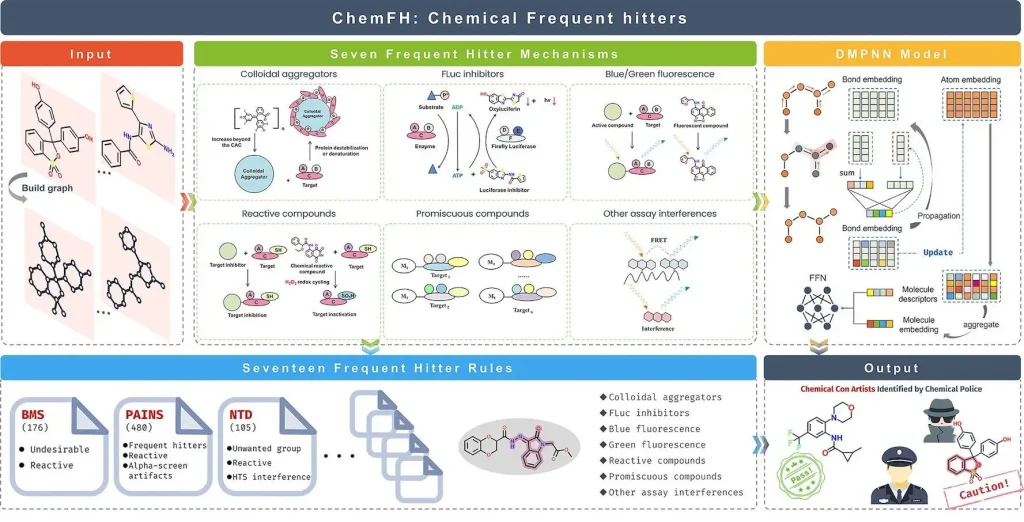
High-quality prediction models with an average AUC value of 0.91 were created by researchers utilizing multi-task directed message-passing network (DMPNN) architectures combined with uncertainty estimates on a dataset comprising 823 391 chemicals. ChemFH also included eleven widely utilized frequent hitter screening rules and 1441 typical alert substructures that were derived from the data that was gathered. A set of 75 external substances was used to validate ChemFH. Then, by applying ChemFH to five virtual screening libraries, its virtual screening capabilities were verified with success. Two natural items and FDA-approved medications were also used for further validation of ChemFH, which produced accurate and dependable results. Drug discovery can be made more effective and successful by using ChemFH, a comprehensive, dependable, and computationally efficient screening pipeline that makes it easier to identify genuine positive test results.
Introduction
Technologies for virtual screening (VS) and high-throughput screening (HTS) are becoming increasingly important in drug development since they increase productivity and help find compounds. In HTS, true positive chemicals usually account for only 0.01-0.1% of samples; false positives and unexpected results are responsible for over 95% of positive results. Often found in various forms of HTS, these substances are referred to as frequent hits (FHs). Chemical interference in fluorescence spectroscopy (FH) is a major problem since it can occur through a variety of mechanisms, such as chemical reactive interference, colloidal aggregation, and disruption of detection techniques. Molecular libraries and HTS data contain a significant number of interfering chemicals, including aggregation, fluorescence, and FLuc inhibitors. These substances, also referred to as chemical con artists, have the potential to seriously impede the development of new drugs and result in a large loss of time and money for research. In a 2014 essay, Baell emphasized how critical it is to resolve these interference mechanisms.
The detrimental impacts of false-positive chemicals have been brought to light in the 2017 American Chemical Society publication, emphasizing assay interference. The study offers researchers advice on how to verify the validity of positive screening results and guard against false positives. For high-throughput screening to reduce wasteful spending, increase screening hit rates, and improve drug development efficiency, false positives must be identified and addressed. The practice of screening compounds for false positives (FH) has long been established. Aggregator Advisor, ALARM NMR, and counter-screen assays are some of the techniques used to find interfering chemicals. These techniques are costly and time-consuming, which is why computational prediction tools like Aggregator Advisor, Luciferase Advisor, and pan-assay interference compounds (PAINS) are more useful. Designed to identify false-positive chemicals, PAINS is a representative filtering method that generates 480 structural alarms. Small training datasets, unclear substructure screening criteria, and inadequate false hit detection techniques are some of the common drawbacks of these tools. Thus, to increase their effectiveness and usefulness in the early phases of drug discovery, high-accuracy FH prediction models or tools must be created.
Understanding ChemFH
ChemFH is an online tool that uses a database of 823,391 substances to provide thorough possible FH prediction and screening. The platform builds reliable FH model predictions using prediction models and a DMPNN framework. The prediction models are enhanced by the Chemprop program, which has 102 typical substructure criteria with excellent detection accuracy. Ten widely used FH screening rules are also included in ChemFH for more thorough detection. Several FH screenings using five virtual screening databases were carried out in order to verify ChemFH and investigate FH distribution using various interference systems. To illustrate the effectiveness and dependability of ChemFH, two representative chemicals—curcumin and chaetocin—were subjected to its application. Early in the drug discovery process, the platform’s sensible implementation might significantly improve efficiency and success rate by triaging compound interference.
ChemFH on Evaluation of FDA-approved drugs
ChemFH is a model for predicting FHs or assay interferences. Researchers have evaluated ChemFH’s prediction power on 2575 FDA-approved medications from DrugBank. According to the research, the proportion of medications displaying test interference varies between 3.65% and 6.44%, with promiscuous substances accounting for 15.03% of the total. in FDA-approved medications, 166 (6.44%) of the colloidal aggregators were expected to be assay interferents, indicating a comparatively low total FH ratio. According to the study, 30.87% of currently approved medications by the FDA would have been missed in their discovery if these filters had rejected them before they were approved. ChemFH’s average prediction accuracy was 0.923, suggesting that the model performs well when it comes to predicting FHs in medications that have received FDA approval.
Conclusions
A comprehensive tool called ChemFH was created to solve the problem of false-positive results in drug development that frequently occur. ChemFH is a comprehensive web platform that assesses typical false positives, making it easier to identify possible false hits with reliable and accurate results. For FH detection and interpretation, it integrates 1441 substructures, including 10 widely used FH screening criteria and representative alarm substructures from gathered data. For smooth process integration and automated high-throughput screening, the website provides an API. The confidence intervals provided by ChemFH’s uncertainty estimate techniques improve the interpretability and dependability of the results.
Article Source: Reference Paper | ChemFH is freely available at Webserver | The dataset and the code necessary to build and evaluate the models are available at https://github.com/antwiser/ChemFH and https://zenodo.org/doi/10.5281/zenodo.11082970.
Follow Us!
Learn More:














{kind=link}