
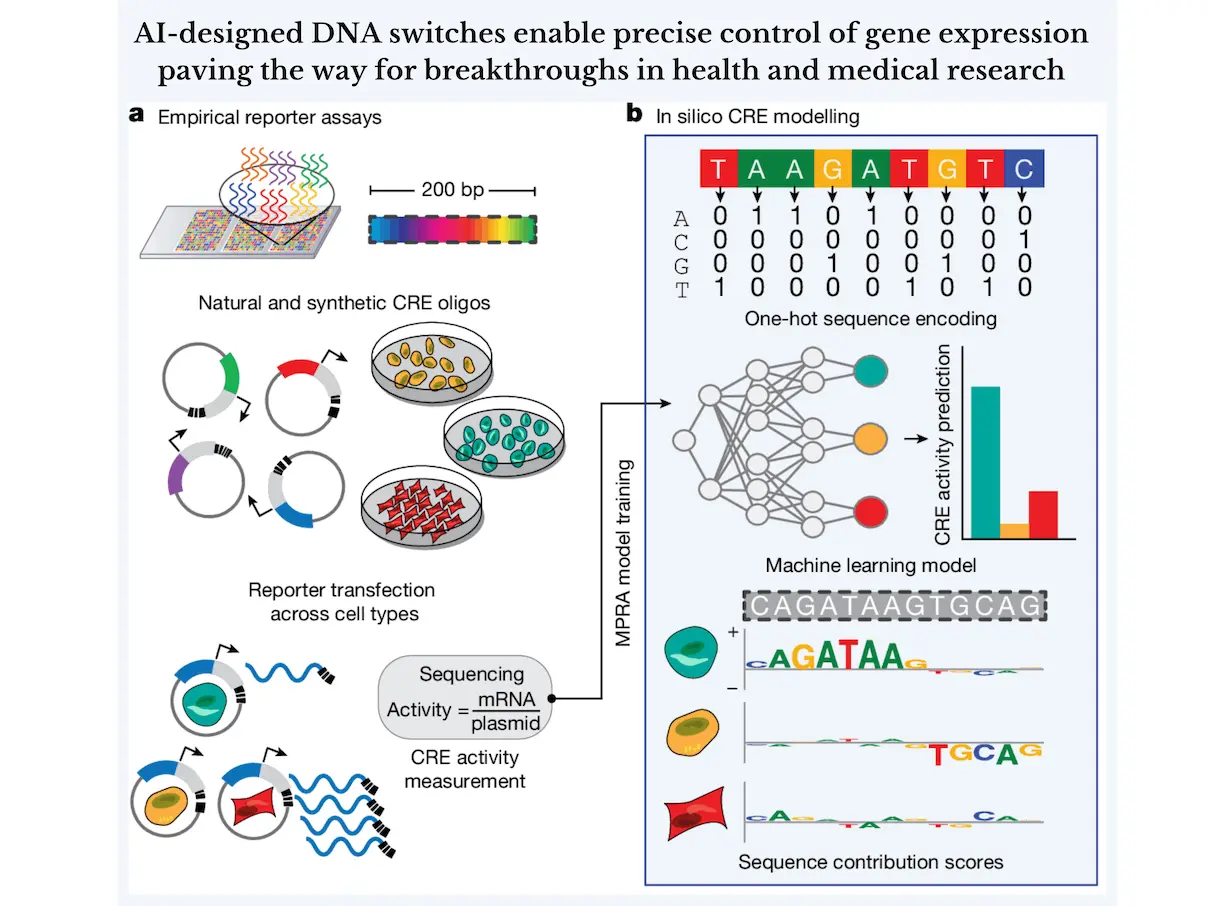
In this day and age, artificial intelligence is everywhere; it’s omnipresent. It is utilized in healthcare, finance, entertainment, IoT, agriculture, marketing, cybersecurity, and so much more! In this article, we dive into the innovative ways researchers have found to integrate AI with genomics. The possibility of tuning the expression of certain genes in organisms has always been fascinating. Researchers at the Jackson Laboratory, the Broad Institute of MIT, and Harvard and Yale University have used AI to design new DNA switches that can control the expression of the genes in various cell types.
The Role of DNA Switches in Gene Expression
DNA switches, called cis-regulatory elements (CREs), control the expression and repression of genes. As we know, every cell in the human body contains DNA (except RBCs and platelets) and hence has the same set of genes. However, not all genes are active in each cell. CREs are not a part of the genes but are located near the genes they control. These CREs are regulatory DNA sequences that decide when and where these genes should be active. For example, they ensure that the liver and brain cells do their specific tasks by activating only the genes needed for those functions. Liver cells need genes for detoxifying compounds, whereas brain cells require genes for signal transmission. CREs help achieve this cellular specialization, yet finding ways to control these switches accurately has remained challenging, especially in gene therapy.
“Natural CREs, while plentiful, represent a tiny fraction of possible genetic elements and are constrained in their function by natural selection,” explained Sager Gosai, a co-first author of the study. Hence, he explained that AI tools have a lot of potential for designing genetic switches that precisely tune gene expression for novel applications without the pressure of evolution.
Challenges in Gene Therapy and the Need for Synthetic CREs
Gene editing methods currently in use affect the entire organism. For that reason, it sometimes becomes undesirable. Targeting the gene editing process for only specific cell types or tissues is far more complicated. Affecting the genes in nontarget cells can impact normal tissues. This is because one does not understand CRE “grammar”: the rules determining how different CREs might control the same genes but across different cell types. Rules are complicated since there is no easy syntax and there is really limited development of cell-specific gene therapies.
“Can we learn to read and write the code of these regulatory elements?” asked Steven Reilly, Ph.D., assistant professor at Yale and senior author of the study. By training deep-learning models, researchers were able to learn a more complex regulatory code capable of predicting and designing synthetic CREs with large specificities.
AI Enables Construction of Cell-Type-Specific CREs
To overcome this challenge, the scientists built an AI model called Malinois, trained it on hundreds of thousands of DNA sequences, and then used deep learning to train it on the activity of CREs in blood, liver, and brain cells. This model might predict the activity of any DNA sequence for the infinite possible combinations. These predictions were analyzed to discover new patterns in DNA and to learn the impact of the grammar of CRE sequences.
Next was the inclusion of Malinois into a platform known as CODA (computational optimization of DNA activity). In this, the synthetic CREs were iteratively designed and improved to achieve the desired cell-type specificity in their activity. This “smart” platform used the predictions by Malinois to optimize the sequences for specific functions, such as turning on a gene specifically in liver cells but not in the brain or blood cells.
Testing the Precision of Synthetic CREs
The team then made thousands of synthetic CREs and transduced them into cells. They measured each CRE’s ability to turn on genes in the target cell types as well as its ability to avoid gene activation in non-target cells. Amazingly, the synthetic CREs were even more cell-specific than the natural ones, making it possible to control gene expression with unprecedented precision.
“What is special about these synthetically designed elements is that they show remarkable specificity to the target cell type they were designed for,” said Ryan Tewhey, Ph.D., associate professor at Jackson Laboratory and a senior author of the study. “This opens the door for us to turn the expression of a gene up or down in just one tissue without affecting the rest of the body.”
This is how synthetic CREs gained specificity: by combining activation sequences that turn on the genes in the target cells with repression sequences that actively suppress the same gene in non-target cells. They combined the information from both activated and deactivated sequences. It was a mix of activation and repression that gave unprecedented precision in cell-type-specific gene regulation, and in medicine, this could be very valuable.
In Vivo Success: Testing CREs in Animals
To test whether these CREs might function in vivo, the researchers tested them in living animals. One synthetic CRE activated a fluorescent protein in zebrafish liver cells but not in any other tissue. This demonstrated that synthetic CREs were selective in a living system.
“Such tools will be valuable for basic research but also could have significant biomedical implications where you could use these elements to control gene expression in very specific cell types for therapeutic purposes,” said Tewhey.
Implications for Future Therapies
This work lays down new possibilities in medicine, agriculture, and biotechnology in the development of DNA “switches” that may one day be used to control any gene in any cell. It has allowed researchers to write DNA codes with targeted functions as they move one step closer toward personalized and highly controlled gene therapy working harmoniously with the body’s natural systems. Applications range from treatment for genetic diseases to biomanufacturing and synthetic biology.
Article Source: Reference Paper | Reference Article | CODA is available on GitHub.
Follow Us!
Learn More:




Neermita Bhattacharya is a consulting Scientific Content Writing Intern at CBIRT. She is pursuing B.Tech in computer science from IIT Jodhpur. She has a niche interest in the amalgamation of biological concepts and computer science and wishes to pursue higher studies in related fields. She has quite a bunch of hobbies- swimming, dancing ballet, playing the violin, guitar, ukulele, singing, drawing and painting, reading novels, playing indie videogames and writing short stories. She is excited to delve deeper into the fields of bioinformatics, genetics and computational biology and possibly help the world through research!











{kind=link}