
The IBM Research – Zurich, scientists proposed a novel biologically-inspired optimizer for artificial and spiking neural networks that consolidate key standards of synaptic plasticity seen in cortical dendrites: GRAPES (Group Responsibility for Adjusting the Propagation of Error Signals). The findings pave the way for researchers to bridge the gap between backpropagation and biologically plausible learning systems.
GRAPES executes a weight-distribution dependent modulation of the error signal at every network node. The scientists showed that this biologically-inspired mechanism prompts a significant improvement in the exhibition of artificial and spiking networks with feedforward, convolutional, and recurrent architectures, it mitigates catastrophic forgetting, and it is ideally appropriate for dedicated hardware implementations.
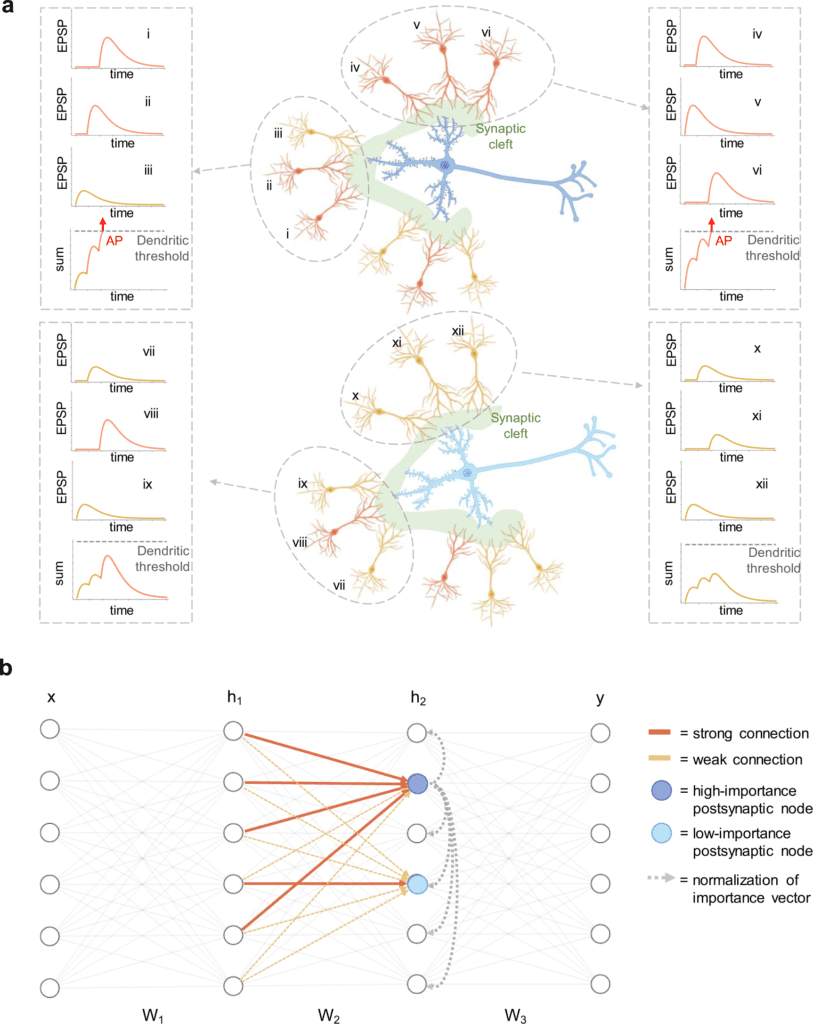
Image Source: Introducing principles of synaptic integration in the optimization of deep neural networks.
Plasticity circuits in the brain are known to be impacted by the dissemination of the synaptic weights through the mechanisms of synaptic integration and local regulation of synaptic strength.
Be that as it may, the perplexing interplay of simulation-dependent plasticity with local learning signals is dismissed by the majority of the artificial neural network training algorithms devised up to this point.
The researchers’ work shows reconciling neurophysiology insights of knowledge with machine intelligence is vital to supporting the performance of neural networks.
The Artificial Neural Networks (ANNs)
Artificial neural networks (ANNs) were proposed in the 1940s as simplified computational models of the neural circuits of the mammalian brain. With the advancements in computing power, ANNs floated away from the neurobiological frameworks they were initially inspired from and reoriented towards the improvement of computational methods utilized in a wide range of applications.
Among the assortment of strategies proposed to train multi-layer neural networks, the backpropagation (BP) algorithm has been demonstrated to lead to an effective training scheme. Despite the amazing progress of machine intelligence, the gap between the capability of ANNs and the brain’s computational power stays to be restricted.
Important issues of ANNs, like long training time, catastrophic forgetting, and inability to take advantage of expanding network complexity, should be managed not exclusively to approach the human brain abilities yet additionally to work on the performance of everyday utilized gadgets. For example, decreasing the training time of online learning in robotic applications is vital to guarantee a quick transformation of the robotic agent to new contexts and diminish the energy costs related to training.
A few techniques, for example, batch normalization, layer normalization, and weight normalization, have been proposed to speed up the training of ANNs. Albeit fruitful in working on the convergence rate, such strategies are a long way behind the learning capacities of the biological brain.
Limitations of ANNs and Overcoming Them
The limitations of ANNs for the brain can be generally credited to the significant simplifications of their structure and dynamics contrasted with the vertebrates’ neural circuits.
A few mechanisms of fundamental significance for brain functioning, counting synaptic integration and local regulation of weight strength, are commonly not modeled in BP-based training of ANNs. Beating this limitation could be vital in bringing artificial networks’ performance nearer to animal intelligence.
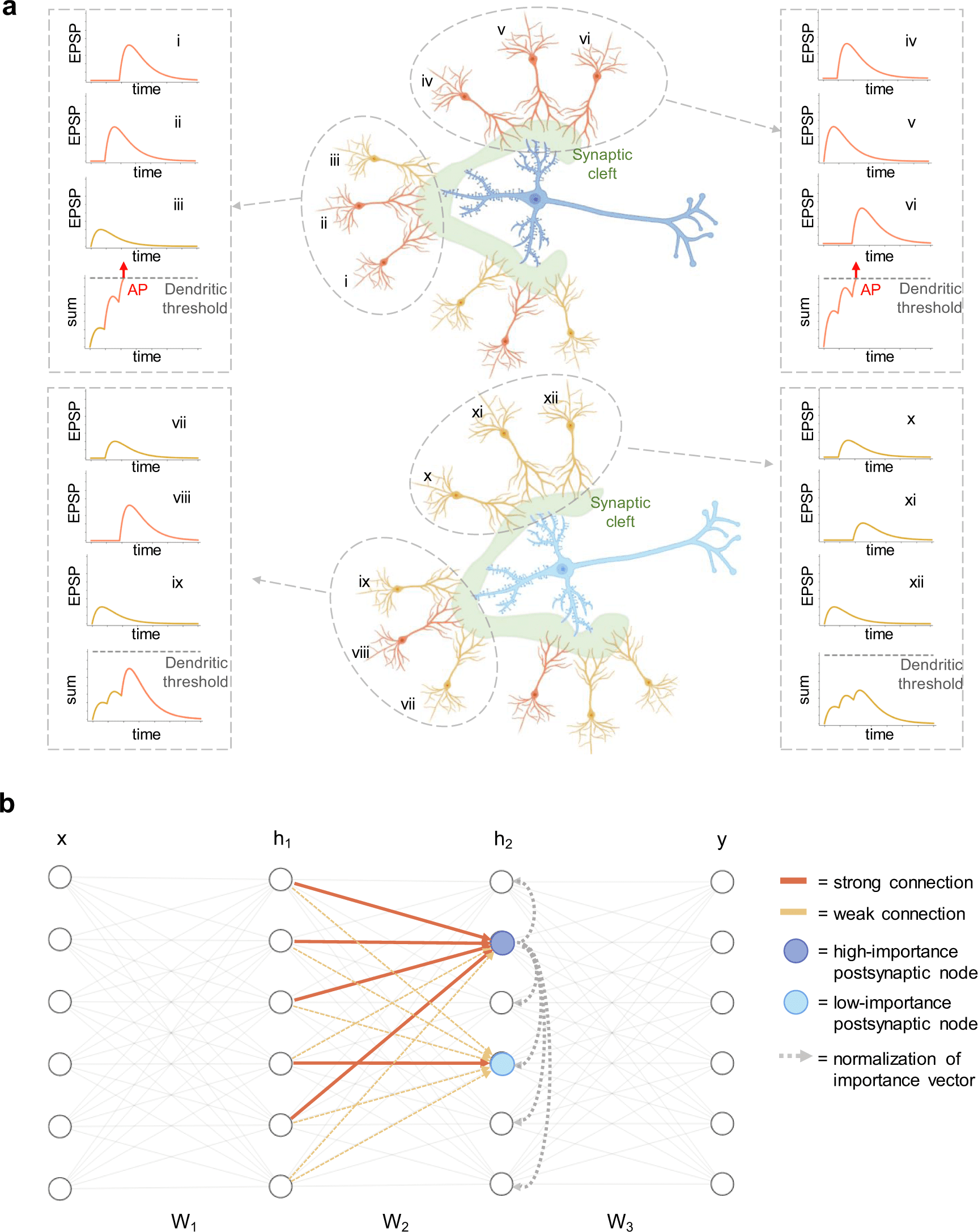
Synaptic integration is the cycle by which neurons consolidate the spike trains obtained by many presynaptic neurons before the generation of action potentials (APs). The axonal APs are elicited in the axon of the cell as a reaction to the input received from the cell’s dendrites and go about as the overall output signal of the neuron.
Experimental proof has shown that, in CA1 cells, input signals arriving at the equivalent postsynaptic cell from different presynaptic neurons might interact with non-linear dynamics because of the active properties of the dendrites. In particular, when strong depolarization happens in a dendritic branch, a dendritic AP is evoked in the region.
The dendritic AP boosts the amplitude of the amount of the excitatory postsynaptic possibilities (EPSPs) that created it, accordingly amplifying the dendritic input before it arrives at the soma to elicit an axonal AP. The generation of a dendritic spike requires enough pre-synaptic cells spatially associated with a similar branch to be active close on schedule with adequate synaptic strength.
As a result, the capacity of synaptic inputs to impact the result of the postsynaptic neuron relies upon their location inside the dendritic tree. The strong computational capabilities of neurons are suggested to come from the complex non-linear dynamics obtained from dendritic spikes.
Accordingly, the local weight distribution can be capable of boosting the input signal at explicit nodes. Correspondingly to neurons in the brain, nodes in ANNs get inputs from numerous cells and produce a single output. Scientists could relate the activation of artificial modes to axonic APs, yet there is no complete translation of the mechanism of dendritic APs into the dynamics of point neurons.
However, dendritic spikes are firmly impacted by the dispersion of synaptic strengths inside dendritic branches. Essentially, the non-linear dynamics of artificial nodes are affected by the weight dissemination of synapses incoming to a layer of nodes. Surprisingly, in like-manner training approaches for ANNs, a mechanism considering the weight dissemination for every node is lacking.
The GRAPES Algorithm
The synaptic integration and the local synaptic strength regulation mechanisms are perplexing cycles that rely upon different factors, like the enormous variability in size, structure, excitability, intercellular distance, and temporal dynamics of neurotransmitters and dendritic spines.
The straightforward point-like design of asynchronously operating ANN node doesn’t permit one to reproduce the rich dynamics empowered by the complex neuronal morphology. Thus, a direct translation of the mechanism of dendritic integration for ANNs isn’t straightforward.
Here, the scientists took motivation from the non-linear synaptic dynamics and introduced a deep learning analyzer to boost the training of FCNNs. They wanted to introduce a robust algorithm enlivened by biological mechanisms and clarify its true capacity to sway the properties of ANNs. This novel methodology can likewise be effortlessly applied to all the more biologically plausible neuronal models like SNNs.
The researchers’ calculation expanded on three perceptions:
- In the brain, because of the spiking nature of the data, a signal is propagated provided that a postsynaptic neuron gets enough input current from the presynaptic populace to evoke APs. In rate-based models of neural activity, a neuron with a high firing rate is bound to produce higher activity in the downstream neurons than neurons with a low firing rate.
- A solitary presynaptic neuron is mindful of just a fraction of the main driving force that drives the postsynaptic neuron to fire. Henceforth, the effect of a presynaptic neuron on the downstream layers relies additionally upon all the other presynaptic neurons associated with the similar postsynaptic cell.
- If the explicit distributions of the sources of inputs are disregarded, the firing probability of a postsynaptic neuron relies upon the average strength of the presynaptic associations. If the average strength is high, the postsynaptic neuron is more liable to arrive at the spiking threshold and, consequently, to further proliferate the data encoded in the presynaptic populace. Hence, the postsynaptic neuron and the related presynaptic population have a high obligation on the network’s output and potential error.
The Endpoint
Propelled by the biological mechanism of non-linear synaptic integration and local synaptic strength regulation, the scientists proposed GRAPES, a novel optimizer for both ANN and SNN training.
GRAPES depends on the novel concept of node significance, which quantifies each node’s responsibility as a function of the local weight distribution inside a layer. Applied to gradient-based optimization algorithms, GRAPES gives a straightforward and effective methodology to dynamically adjust the error signal at every node and improve the updates of the most relevant parameters.
Contrasted with optimizers like momentum, this latest approach doesn’t have to store parameters from the previous steps, keeping away from extra memory penalty. This characteristic makes GRAPES more biologically plausible than momentum-based optimizers, as neural circuits can’t hold a significant fraction of data from previous states.
The scientists validated their methodology with ANNs on five static data sets (MNIST, CIFAR-10, CIFAR-100, Fashion MNIST, and Extended MNIST) and SNNs on the temporal rate-coded MNIST. They effectively applied GRAPES to various training techniques for supervised learning, particularly BP, FA, and DFA, and to various optimizers, i.e., SGD, RMSprop, and NAG.
The scientists demonstrated that the proposed weight-based modulation prompts higher classification precision and quicker convergence rate both in ANNs and SNNs. Then, they showed that GRAPES addresses significant limitations of ANNs, including alleviation of performance saturation for expanding network complexity and catastrophic forgetting.
To conclude, the researchers’ discoveries show that incorporating GRAPES, more generally brain-inspired local factors in the optimization of neural networks makes way for essential advancement in the performance of biologically inspired learning algorithms and the designing of novel neuromorphic computing technologies.
Article Source: Dellaferrera, G., Woźniak, S., Indiveri, G. et al. Introducing principles of synaptic integration in the optimization of deep neural networks. Nat Commun 13, 1885 (2022). https://doi.org/10.1038/s41467-022-29491-2
Learn More:
Top Bioinformatics Books ↗
Learn more to get deeper insights into the field of bioinformatics.
Top Free Online Bioinformatics Courses ↗
Freely available courses to learn each and every aspect of bioinformatics.
Latest Bioinformatics Breakthroughs ↗
Stay updated with the latest discoveries in the field of bioinformatics.
Tanveen Kaur is a consulting intern at CBIRT, currently, she's pursuing post-graduation in Biotechnology from Shoolini University, Himachal Pradesh. Her interests primarily lay in researching the new advancements in the world of biotechnology and bioinformatics, having a dream of being one of the best researchers.









{kind=link}