
In the ever-evolving field of bioinformatics, automation has become a necessity for handling complex genomic data efficiently. A recent study by researchers at Hong Kong University of Science and Technology, China, presents BioMaster, a multi-agent system designed to streamline bioinformatics workflows. Integrating specialized AI agents, BioMaster enhances automation, error handling, and data validation, making it a robust tool for researchers dealing with large-scale biological data.
The Need for Automated Bioinformatics Workflows
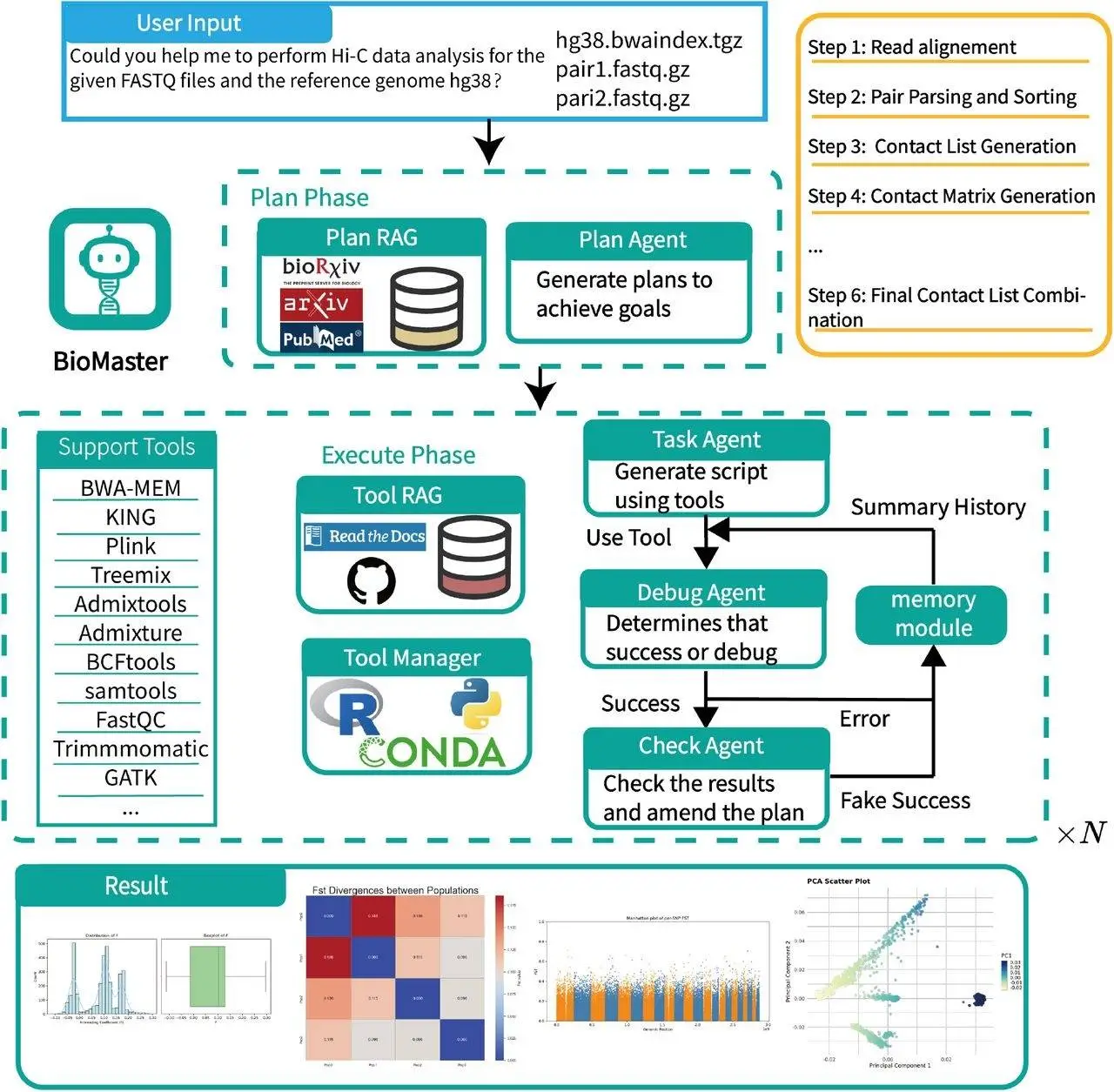
Bioinformatics workflows are comprehensive, ranging from raw data processing to multi-level genetics analysis in broad strokes. All existing computational tools require users to step in at numerous places and remember everything they have done, which are some of the most common sources of inefficiency and mistakes. Existing AI solutions like AutoBA or ChatGPT have tried to improve these processes but struggle with long and complex workflows. BioMaster steps in with a solution to these challenges by utilizing a multi-agent system that optimizes offloading tasks and debugging while maintaining precision and dependability.
How BioMaster Works
BioMaster works based on a multi-agents framework where agents perform different functions as follows:
- Plan Agent: Decomposes bioinformatics task structure into definable steps according to user queries.
- Task Agent: Utilizes a comprehensive knowledge base to convert the defined steps into actionable commands.
- Debug Agent: Monitors the execution process and corrects execution errors.
- Check Agent: Confirms outputs to ensure they are as expected and do not contradict the previously set parameters.
Incorporating Retrieval-Augmented Generation (RAG) ensures that all tasks are performed precisely by retrieving relevant domain-specific knowledge.
Performance Comparison
Comparative studies were performed utilizing GPT-4o as the focus model to help evaluate its efficiency. The bioinformatics processes that were studied include ChIP-seq, single-cell and population genetics, RNA-seq, and Hi-C data processing at a range of levels.
The results demonstrated that BioMaster performs comparably to other methods for simpler tasks like RNA-seq and ChIP-seq. However, for more complex workflows such as population genetics and Hi-C data preprocessing, BioMaster outperformed both AutoBA and ChatGPT. The Check Agent proved particularly valuable in preventing cascading errors by verifying outputs at every step.
The Role of Key Components
Ablation studies focused on the key components of BioMaster were conducted to gain a deeper understanding. Leaving out the plan RAG resulted in partial execution of workflows. Without Plan RAG, workflows performed well under this condition, but longer tasks failed with ample error. Removing Tool RAG resulted in inadequate performance for specialty tasks such as SmartPCA, f4 admix tools, and other bioinformatics tasks, as detailed instructions are critical for these.
What Makes BioMaster Unique?
Unlike single-agent frameworks, BioMaster has a modular multi-agent structure that makes it unique. The task decomposition done by information agents enables reliable task execution through the collaboration of agents. Domain knowledge enables precise execution of the workflows, while rigorous validation deals with common problems such as incorrect file dependency, conflict, etc.
Conclusion
BioMaster is the solution that resolves challenges in bioinformatics automation. It is exact and efficient because of advanced planning, execution, and validation techniques that well exceed the capability of current frameworks. The relentless evolution of AI technology makes BioMaster’s approach tremendously scalable and intelligent to be implemented within bioinformatics.
Article Source: Reference Paper | BioMaster is available on GitHub.
Disclaimer:
The research discussed in this article was conducted and published by the authors of the referenced paper. CBIRT has no involvement in the research itself. This article is intended solely to raise awareness about recent developments and does not claim authorship or endorsement of the research.
Important Note: arXxiv releases preprints that have not yet undergone peer review. As a result, it is important to note that these papers should not be considered conclusive evidence, nor should they be used to direct clinical practice or influence health-related behavior. It is also important to understand that the information presented in these papers is not yet considered established or confirmed.
Follow Us!
Learn More:




Anchal is a consulting scientific writing intern at CBIRT with a passion for bioinformatics and its miracles. She is pursuing an MTech in Bioinformatics from Delhi Technological University, Delhi. Through engaging prose, she invites readers to explore the captivating world of bioinformatics, showcasing its groundbreaking contributions to understanding the mysteries of life. Besides science, she enjoys reading and painting.











{kind=link}